DMR - Docker Model Runner
Introducing the Docker Model Runner (DMR): Running LLMs Outside the Container
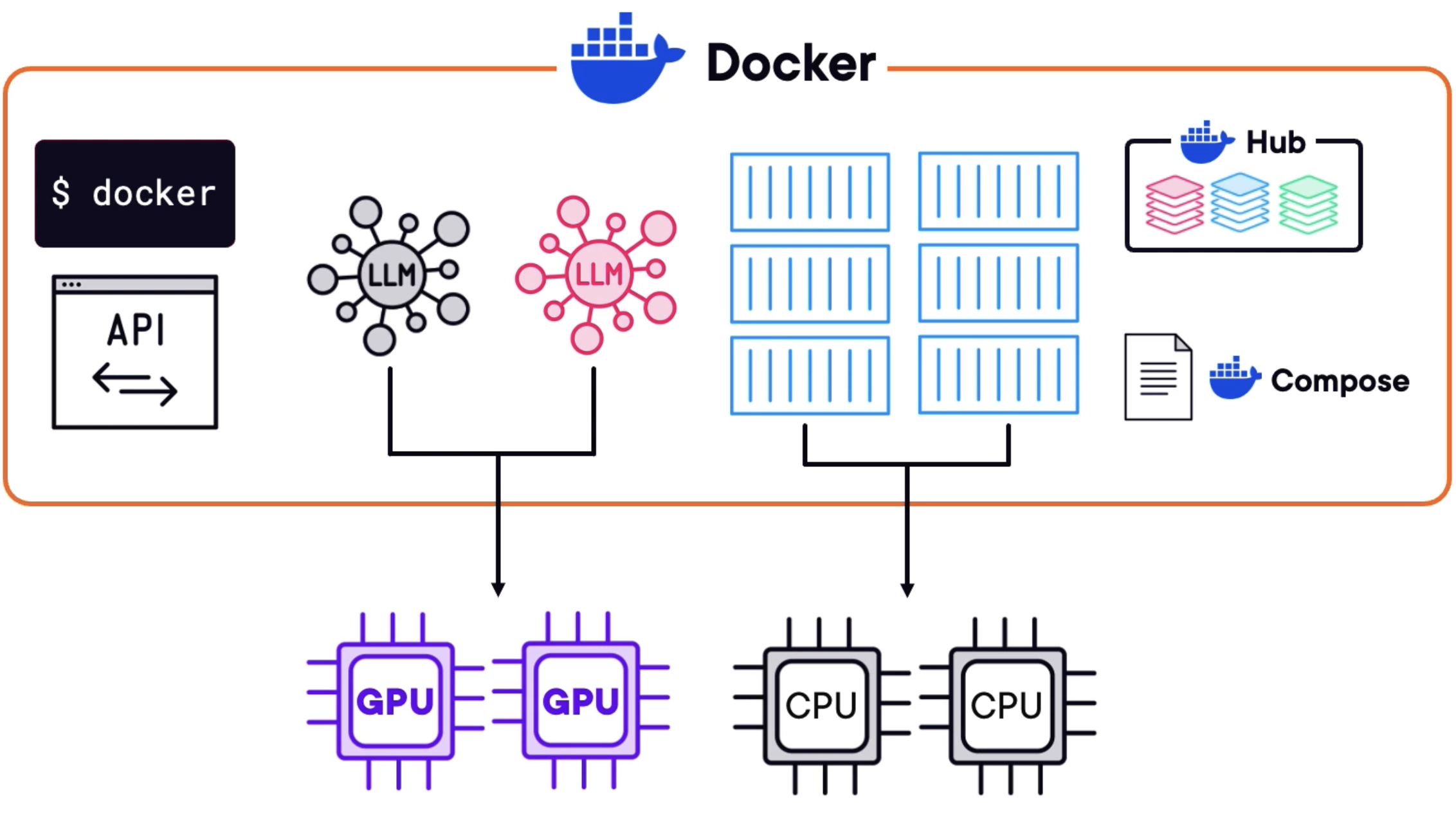
If you're interested in the local AI space (running AI models on local hardware instead of the cloud), you know that running models inside traditional Docker containers is "a bit rubbish." The slow performance and complexity associated with using containers for AI inference led Docker to develop a revolutionary new solution: the Docker Model Runner (DMR).
The most crucial concept of the DMR is that it runs AI models outside of containers.
Key Concepts of the Docker Model Runner
| Concept | Description |
|---|---|
| What It Is | A Docker-native tool for running LLMs and other AI models. |
| Why It's Needed | To solve the problem of painfully slow performance and the difficulty of accessing specialized acceleration hardware (like GPUs) from inside a container. |
| How It Works | It runs the model and inference process outside of a container, but it's seamlessly integrated with the Docker ecosystem. |
| Integration | It uses the same Docker API and command line and is fully integrated with familiar tools like Docker Hub and Docker Compose. |
The Core Problem: Why Containers Fail for LLMs
The primary reason DMR was created stems from a core technical challenge in AI: Acceleration Hardware.
- AI Models Need Acceleration: LLMs and other AI models are computationally intensive. While they can run on regular CPUs, they are painfully slow—almost certainly not fit for real-world use.
- The Need for Specialized "PUs": To be useful, models must run on specialized AI acceleration devices, such as:
- GPUs (Graphics Processing Units)
- NPUs (Neural Processing Units)
- TPUs (Tensor Processing Units)
- The "Hard to Access" Barrier: These specialized hardware devices are "really hard" to access from inside a container. Currently, the only ones realistically accessible are CUDA-enabled NVIDIA GPUs, and even for those, you need to install a complex, specialized NVIDIA toolkit for containers.
Docker's Unthinkable Solution
Instead of attempting to "boil the ocean" by trying to support every piece of current and future acceleration hardware, Docker built a system that fundamentally changes where the model runs.
The DMR allows you to:
- Keep the rest of your application (like your chatbot code and all other microservices) still running in containers.
- Handle the models and the entire inference process outside of containers, where they have full, optimized access to the necessary acceleration hardware.
The result is a slick solution that looks, smells, and feels just like Docker, but finally delivers the real-world performance that modern AI demands.
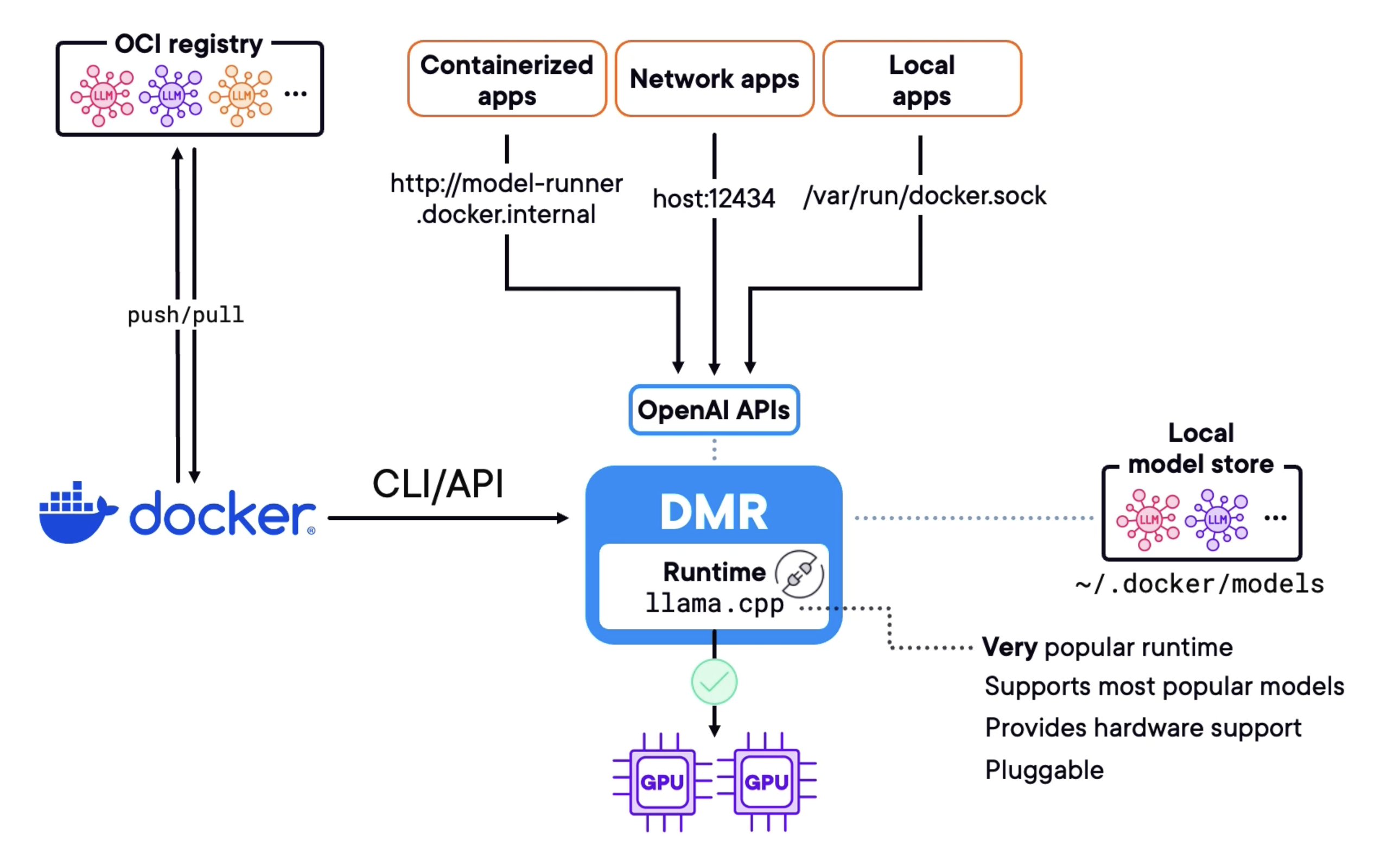
DMR Architecture
Want to discuss cloud architecture? Find me on LinkedIn.
Found this useful? Let's go deeper.
Book a free 15-minute call to discuss your cloud, DevOps, or AI strategy challenges.